|
|
Nguyen-Khang PHAM Lecturer Can Tho University College of information technology 1 Ly Tu Trong, Can Tho City E-mail : pnkhang@cit.ctu.edu.vn |

Image mining with Correspondence Analysis
All scripts and binary for Linux 32All scripts and binary for Linux 64
Binary for Windows (Cygwin), can be used with above scripts
Image2Viz for Windows with GUI (easy to use but slow !!!)
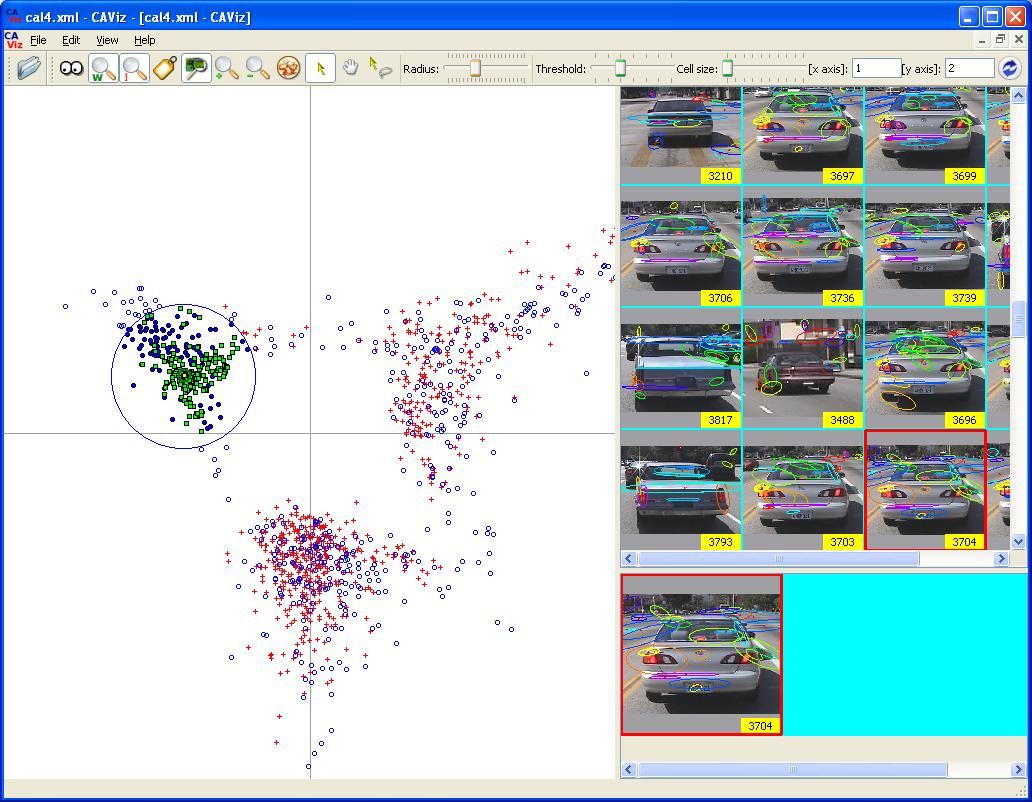
Hierarachical Correspondence Analysis by Visualization (HCAViz)
Caltech-4 Data for HCAViz (open cal4.xml with HCAViz)
I. SCRIPTS
1. image2sift.sh
Compute SIFT for an image
2. dir2sift.sh
Compute SIFT for a directory of images
3. sampling.sh
Sample a subset of SIFT to create visual words using k-means
Syntax: sampling.sh "SIFT-DIR" "RESULT-FILE" [size]
-SIFT-DIR: directory containing SIFT file (output of dir2sift)
-RESULT-FILE: file containing SIFT
-SIZE: number of images used for sampling, by fault, 1/5 images in SIFT-DIR will be used
4. all-steps.sh: all of preprocessing steps used to create data for visualization
II. BINARIES
1. extract_features.ln
Compute SIFT for an image (program of Krystian.Mikolajczyk)
2. kmeans, kmeans-mt:
k-means algorithm implemented by PHAM Nguyen-Khang
Syntax kmeans [OPTION] "data file" "model file"
OPTIONS:
-i : Number of iterations [default: 30]
-k : Number of clusters
-b : Block size [number of lines to be processed per block]
-m : File containing the min cluster of individus, [don't care]
-p : Number of threads [default: 4]
data file format:
number_of_line number_of_column
line1
line2
...
kmeans-mt: version multithreading of kmeans
3. assign, assign-mt:
assign SIFTs of images into clusters to form the contingency table (used for Correspondence Analysis)
Syntax: assign [OPTION] "list file" "model file" "result file"
OPTIONS:
-t : SIFT type [0: no region, 1: output of 'extract_feature' with option -o1]
-d : SIFT region descriptor's directory
-b : Block size [number of lines to be processed per block]
-p : Number of threads [default: 4]
list file: a file containing a list of filename
Format:
number of files (e.g. 10)
file_name_1
file_name_2
...
file_name_10
Use the Linux command 'find' to create this file
model file: clusters computed by k-means
result file: contingency table
4. ca
apply correspondence analysis on a contingency table
Syntax: ca [OPTION] "data file" "output stem"
OPTIONS:
-k number of axes
data file: contingency table
output stemp: stemp for output, the output composes:
_Z.txt: projection of lines
_W.txt: projection of columns
_P.txt: marginal probability of lines
_Q.txt: marginal probability of columns
_A.txt: transistion matrix for projection of lines,
_B.txt: transistion matrix for projection of columns,
Z = P^(-1)*F*A
W = Q^(-1)*F'*B
F: the contingency table,
Q, P: the diagonal matrix